1The Hong Kong University of Science and Technology (Guangzhou)
2Shenzhen University 3Beijing Jiaotong University
4The Chinese University of Hong Kong, Shenzhen
Does multi-view demonstration truly improve robot manipulation, or merely enhance cross-view robustness? We present a systematic study quantifying the performance gains, scaling behavior, and underlying mechanisms of multi-view data for robot manipulation. Controlled experiments show that multi-view demonstrations consistently improve single-view policy success even when evaluation is restricted to the original viewpoint. Notably, multi-view data breaks the scaling limitation of single-view datasets and continues to raise performance ceilings after saturation. To address the scarcity of multi-view data, we propose RoboNVS, a geometry-aware self-supervised framework that synthesizes novel-view videos from monocular inputs. Our generated data consistently improves downstream policies in both simulation and real-world environments.
Understanding Multi-View Gains in Robot Learning
While multi-view demonstrations are known to improve robustness to camera shifts, we investigated whether they fundamentally enhance manipulation capabilities. By isolating viewpoint diversity and evaluating all policies from a single canonical camera, we ensured performance gains were not simply due to test-time view availability.
Finding 1: Improves manipulation performance. Multi-view supervision consistently increases success rates, especially in visually diverse environments where reliance on view-specific cues is high.
Finding 2: Transfers to VLA models. The benefits extend to large, pretrained Vision-Language-Action models, improving success rates across both seen and unseen tasks.
Finding 3: Moderate diversity works best. Performance gains are non-monotonic; an intermediate number of added views (4-8) yields peak results, avoiding the noise of excessive appearance variation.
Finding 4: Moderate magnitude offsets are optimal. Viewpoint shifts between ±10° and ±40° enrich geometric cues effectively, whereas larger shifts (±50°+) introduce hindering appearance changes.
Finding 5: Scales with additional demonstrations. Increasing the number of demonstrations per added view steadily improves policy performance without early saturation.
Finding 6: Breaks single-view saturation. Unlike single-view training, which plateaus as data increases, multi-view training continues to climb, overcoming traditional scaling ceilings.
Internal Mechanisms: Multi-view supervision reshapes visual representations to focus on manipulation-relevant regions (like the end-effector and objects) rather than the background. It also improves action head robustness and stabilizes optimization dynamics.
➜ Motivated by these insights, we propose RoboNVS to synthesize high-quality multi-view demonstrations from monocular inputs.
RoboNVS: Synthesizing Multi-View Demonstrations
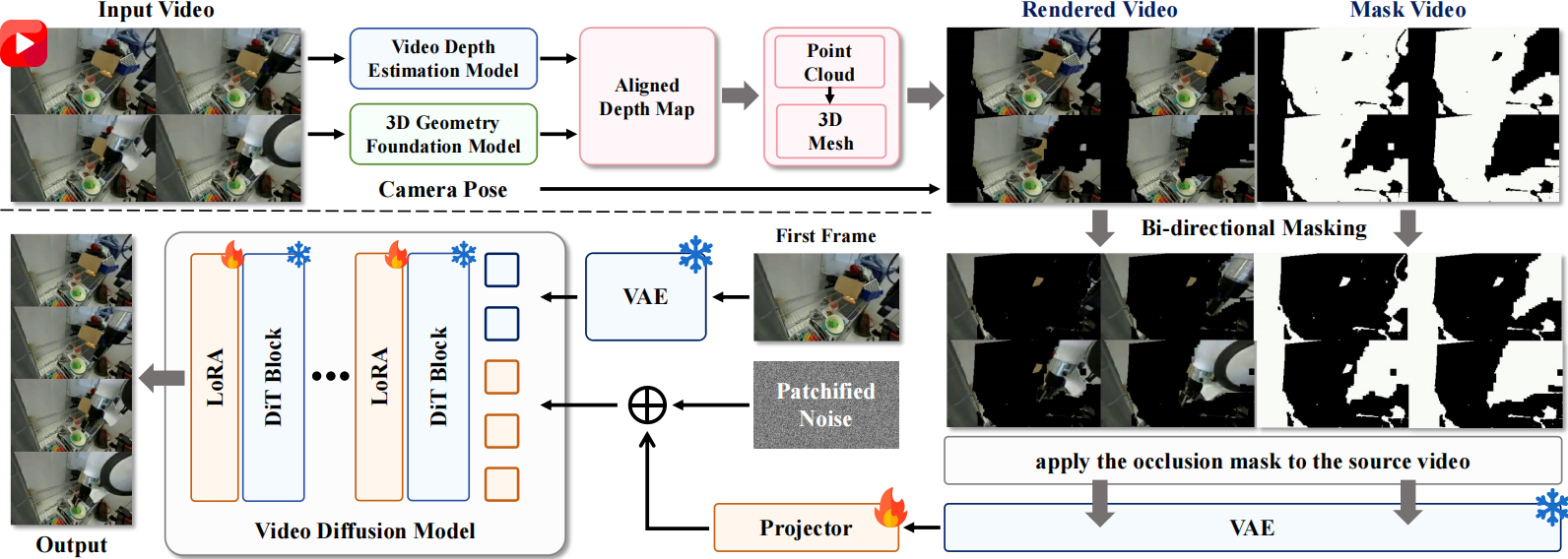
To overcome the scarcity of multi-view data, we propose RoboNVS, a geometry-aware framework that synthesizes novel-view videos from a single monocular demonstration. Why Geometry Matters? Direct video generation often fails in robotics due to geometric inconsistency (e.g., distorted objects or hallucinated structures). Therefore, we explicitly incorporate 3D geometry as a strong prior.
Overview: RoboNVS reconstructs 3D geometry from monocular video, renders it under new viewpoints, and uses diffusion-based inpainting to generate physically consistent novel-view videos.
Key Innovation 1: Depth Alignment
Problem: Monocular depth estimation faces a trade-off:
Relative: Temporally consistent but lacks scale.
Metric: Geometrically correct but temporally unstable.
Solution: We align the two using a global scale-shift transformation, combining temporal consistency with geometric accuracy.
Key Innovation 2: Bi-directional Masking
Problem: Standard inpainting suffers from mismatch between training masks and real occlusions caused by viewpoint changes.
Solution: We train with both directions:
Original mask: Learns object reconstruction.
Inverse mask: Learns background completion.
Together, these designs enable RoboNVS to generate geometrically consistent, temporally stable, and physically plausible novel-view demonstrations.
Extensive Visual Comparison
Source Video(Target View: Right 20° Yaw)
RoboNVS (Ours)(Top: Mask | Bottom: RGB)
RoboNVS (Ablation)(Top: Mask | Bottom: RGB)
EX-4D(Top: Mask | Bottom: RGB)
TrajectoryCrafter(Top: Mask | Bottom: RGB)
CogNVS(Top: Mask | Bottom: RGB)
ZeroNVS-ft(Top: Mask | Bottom: RGB)
ReCamMaster(Top: Mask | Bottom: RGB)
Source Video(Target View: Right 10° Yaw)
RoboNVS (Ours)(Top: Mask | Bottom: RGB)
RoboNVS (Ablation)(Top: Mask | Bottom: RGB)
EX-4D(Top: Mask | Bottom: RGB)
TrajectoryCrafter(Top: Mask | Bottom: RGB)
CogNVS(Top: Mask | Bottom: RGB)
ZeroNVS-ft(Top: Mask | Bottom: RGB)
ReCamMaster(Top: Mask | Bottom: RGB)
Source Video(Target View: Right 20° Yaw)
RoboNVS (Ours)(Top: Mask | Bottom: RGB)
RoboNVS (Ablation)(Top: Mask | Bottom: RGB)
EX-4D(Top: Mask | Bottom: RGB)
TrajectoryCrafter(Top: Mask | Bottom: RGB)
CogNVS(Top: Mask | Bottom: RGB)
ZeroNVS-ft(Top: Mask | Bottom: RGB)
ReCamMaster(Top: Mask | Bottom: RGB)
Source Video(Target View: Left 10° Yaw)
RoboNVS (Ours)(Top: Mask | Bottom: RGB)
RoboNVS (Ablation)(Top: Mask | Bottom: RGB)
EX-4D(Top: Mask | Bottom: RGB)
TrajectoryCrafter(Top: Mask | Bottom: RGB)
CogNVS(Top: Mask | Bottom: RGB)
ZeroNVS-ft(Top: Mask | Bottom: RGB)
ReCamMaster(Top: Mask | Bottom: RGB)
Source Video(Target View: Right 20° Yaw)
RoboNVS (Ours)(Top: Mask | Bottom: RGB)
RoboNVS (Ablation)(Top: Mask | Bottom: RGB)
EX-4D(Top: Mask | Bottom: RGB)
TrajectoryCrafter(Top: Mask | Bottom: RGB)
CogNVS(Top: Mask | Bottom: RGB)
ZeroNVS-ft(Top: Mask | Bottom: RGB)
ReCamMaster(Top: Mask | Bottom: RGB)
Experimental Results
We evaluate the efficacy of our method across three challenging manipulation tasks.
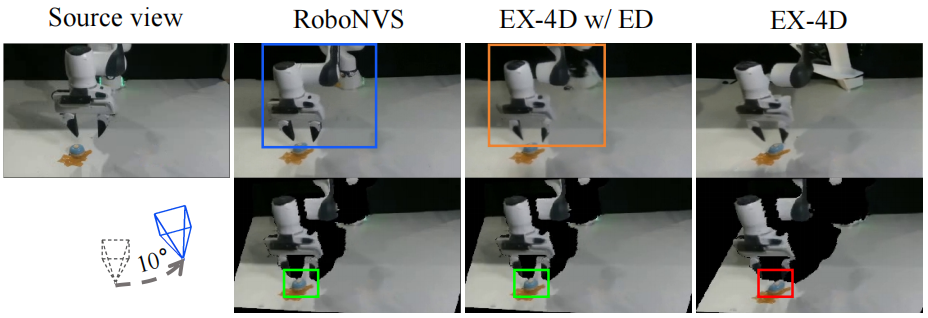
We compare four data augmentation configurations:
(1) Baseline (Monocular only), which uses no augmentation;
(2) EX-4D;
(3) EX-4D w/ Depth Alignment (EX-4D w/ DA); and
(4) RoboNVS (Ours).
For all augmentation-based methods, we generate four synthetic views at specified camera trajectories
({−20°, −10°, 10°, 20°}) to augment the training set.
A Diffusion Policy is then trained on each augmented dataset. We report the success rates
evaluated under the base-view to demonstrate how synthesized multi-view data provides
geometric priors for robust manipulation.
Figure 1. Real-world Setup. Our evaluation environment and the three manipulation tasks: Click Bell, Pick Fruit, and Pick Lego. Each task requires precise geometric understanding of the target objects.
Figure 2. Qualitative Comparison. Visual results in real-world scenarios. RoboNVS demonstrates superior performance in both geometry reconstruction and mask completion quality compared to existing baselines.
Method
Click Bell
Pick Fruit
Pick Lego
Baseline (Monocular only)
25%
10%
5%
EX-4D
40%
35%
30%
EX-4D w/ Depth Alignment
50%
40%
40%
RoboNVS (Ours)
70%
60%
65%
Table 1. Success Rate Comparison. Mean success rates over multiple trials. RoboNVS significantly outperforms existing methods by providing high-fidelity synthetic data.
BibTeX
If you find our work useful in your research, please consider citing:
@misc{cai2026viewpointgeneralizationmultiviewdemonstrations,
title={Beyond Viewpoint Generalization: What Multi-View Demonstrations Offer and How to Synthesize Them for Robot Manipulation?},
author={Boyang Cai and Qiwei Liang and Jiawei Li and Shihang Weng and Zhaoxin Zhang and Tao Lin and Xiangyu Chen and Wenjie Zhang and Jiaqi Mao and Weisheng Xu and Bin Yang and Jiaming Liang and Junhao Cai and Renjing Xu},
year={2026},
eprint={2603.26757},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.26757},
}